During my time at the Recurse Center I’m working on some of the gaps from not majoring computer science in college (although I did get close to a minor!). When I compare my skills against say, the requirements for admission to a CS grad program, the thing I notice missing is a strong foundation in algorithms and their good friends, data structures.
What’s an algorithm?
Obviously magic. Just kidding. The word algorithm is really intimidating and sounds scary, but it’s almost (almost) synonymous with “solution to a problem.” Ex. given this set of constraints and this question, how do you answer it? That’s pretty much algorithms.
Data structures are good friends with algorithms, because once you put data in the “right” data structure for a problem, it becomes so much easier to solve that problem. It looks like understanding algorithms and data structures (theory + practice) is the way to go if you want to understand them.
Trees in general
Trees are a data type where the elements generally have a relationship to each other. When you see a tree drawn out (what I would call theoretically, cause unless you use a visual programming language, your code doesn’t look like this), you use words common to real trees, such as root, leaf, branch, and node (okay not that one). The Wikipedia tree article has a nice list of the terms.
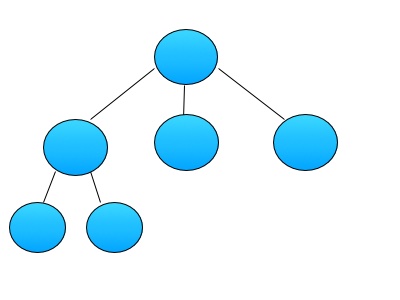
You’d call the circle at the top of the image the root, because it’s the top node in the tree, and the circles at the bottom are leaves because they have no nodes beneath them. This image doesn’t have arrows, but pretend they’re all pointed down.
Trees in practice
When I started this week saying “I want to work on some data structures!” and realized that starting with implementing Dijkstra’s algorithm may have been a tad ambitious, I worked with an HS resident to discuss, and then implement a trie data structure. There are lots of different kinds of trees (makes sense, because trees an ADT, or abstract data type), of which trie is one.
How to you pronounce “trie”?
Great question! Unfortunately, the person naming this data structure was too clever (never be clever in naming!) and it’s pronounced the same as “tree.” However, in practice, people refer to it as “try-ee” to attempt to differentiate the two.
What’s a trie?
To rephrase wikipedia, trie is a data structure that stores an associative array (ex. “dictionary”) of data where the keys are most often strings. Let’s say you had a hypothetical application that autosuggests the rest of the word. Let’s say that app isn’t just say searching for matching among titles of your documentation articles (a smaller data set), but is searching among, you know, English.

It would be super duper slow to search ALL ENGLISH WORDS every time you wanted to say “I have h, now what’s possible? I have he, now what’s possible?” The trie data structure is especially good at solving this. If I want to find out all possible words for a given starting string, I only have to navigate down those paths of the trie, not through the entire set of data.
Implementing a trie
During week one, part of my frustration with algorithms was feeling like I could study and memorize, but without implementation (oh hi, data structures!) they didn’t matter. So talking about trees and tries without implementation was meh. So I wrote an implementation in JavaScript/Node.
First, I created a structure for a node. I called it a node so I could remember this
treeParty.Node = function (val) {
return { value: val,
children: []
}
}Next, I needed to be able to add a word to the data structure. First, I have to make sure I don’t accidentally add another node for an existing letter at an existing layer (“no dupes” is something I seem to hear a lot around making sure something is fast). Ex. I only want one sub-tree for when the first letter is ‘h’. If the letter/node exists, then we go ahead and assign that as the next “parent” node to explore. If it doesn’t, make a new node, add it to the parent’s children, and then call the function again with the new node as the parent, until the word is no longer explorable.
treeParty.makeTree = function treeMaker(parent, word) {
if(word.length > 0) {
var existsArray = parent.children.filter(function(item) { return item.value == word[0] })
var n
if(existsArray.length == 0){
n = new this.Node(word[0])
parent.children.push(n)
} else {
n = existsArray[0]
}
this.makeTree(n, word.slice(1))
}
}I implemented the trie with test-driven development. I was curious about doing TDD in node without a testing framework (using boring old “assert”s)
I start my test file with assert and my treeParty module:
var assert = require('assert')
var t = require('../src/trees.js')
assert(typeof t == 'object')
Then I made a root node, and tested that if I added a word to it, that the root’s children contained one element (“h”).
var root = new t.Node() // undefined node
assert(root.value == undefined)
var word = 'hello'
t.makeTree(root, word)
assert(root.children.length == 1)The whole exploration is on github under tree-party if you’d like to check it out.